magley's website
Blog
Алгоритми и структуре података у широкој фази
Стабла, сецање и велико O

Битан део погона за игре и разног геопросторног софтвера је појам пресека између објеката. Објекти су представљени подацима (у играма ентитети имају положај и облик, док у базама података ентитети су мултимодалне тачке). Желимо да пронађемо све сударе (колизије) између ових објеката, или да пронађемо најближе суседе било ког објекта.
Очигледно решење у којем се скенира сваки пар (или свака $n$-торка) је сувише споро за стварне податке, и стога морамо пронаћи начин да брзо исечемо лажне негативе или да групишемо потенцијалне кандидате заједно. У овом чланку ћу покрити нека од ових решења.
Уколико само желите резултате, прескочите овде. Изворни код за све имплементације се могу пронаћи у овом гитхаб репозиторијуму.
Метрички простори
Ипак смо ми сви одрасли људи па хајде да формализујемо ствари. Метрички простор чини скуп објеката $M$, који може бити било шта, и функција удаљености $d : M \times M \to \mathbb{R}$. Дакле ако имате скуп ствари неког типа, и можеш дефинисати ,,удаљености" између било које две ствари, добијате метрички простор. Та функција дистанце се зове метрика, и можете користити ту метрику за мерење и других ствари поред удаљености између два објекта у скупу. Метрика мора да задовољи следеће особине:
- p.1$\quad d(x, x) = 0$
- p.2$\quad d(a, b) = d(b, a)$
- p.3$\quad d(a, b) > 0, \quad a \neq b$
- p.4$\quad d(a, b) + d(b, c) \ge d(a, c)$
Еуклидовски простор је типичан пример метричког простора. Ми на тај начин
доживљавамо свет, тај простор користе игре, и то је обично оно на шта мислимо
када кажемо “простор”: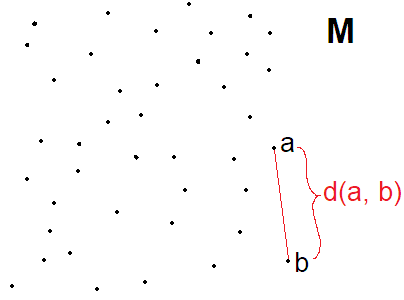
У сложенијим случајевима где имате податке различитог типа и ниједан од њих не представља положај у стварном свету, морате бити креативнији. Но, докле год је могуће измерити удаљеност између два објекта и та мера задовољава особине описане изнад, то је метрички простор, без обзира на то колико се функција мере чини неинтуитивном.
Овде се бавимо еуклидовским простором пошто је чланак писан за погоне за игре али и зато што је лако и интуитивно визуализовати тај простор.
Шта уопште значи пресек у контексту метричког простора? Сваки елемент у
метричком простору је тачка, и стога они немају облик. Без облика не можемо
причати о пресеку. Између две тачке није могућ пресек јер $d(a, b) = 0
\xRightarrow{\text{p.1}} a = b$.
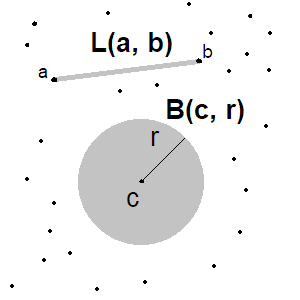
Није довољно да причамо само о метричком простору. Лопта $B$ полупречника $r$ са центром у $c$ је подскуп метричког простора дефинисан на следећи начин:
$$B(c, r) = \{ x \in M \mid d(c, x) < r \} $$
Дуж је скуп тачака који се може дефинисати параметарском једначином:
$$L(a, b) = \{ (1 - t)a + tb \mid t \in [0, 1] \}$$
Погледајте слику испод. Напоменућу да нисам уопште разматрао појам граница: лопта може али не мора да укључује тачке на својој граници ($d(c, x) \leq r$ или $d(c, x) < r$). Обично су лопте ,,отворене" што значи да граница није укључена. Али у нашој дефиницији дужи пише $t \in [0, 1]$ што укључује и крајње тачке $a$ и $b$. У пракси ми никад нећемо радити са непрекидним просторима због природног ограничења хардвера, те је овај проблем елиминисан кроз жртвовања прецизности.
Многоуглови су зезнути: кренућемо од уније дужи такве да свака крајња тачка припада тачно $2$ дужи (попут затвореног ланца):
$$P(p_1, p_2, …, p_n) = L(p_1, p_2) \cup L(p_2, p_3) \cup … \cup L(p_{n-1}, p_n)$$
Тиме је покривена граница многоугла; а шта је са унутрашњости? Па, морамо прво дефинисати шта је унутрашњост. Погледајте следећу слику:
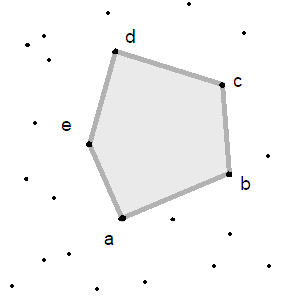
На основу чега ми знамо да је осенчена површина унутрашњост од $P(a,b,c,d,e)$? Не постоји довољно информација тренутно да можемо то претпоставити. Теорема Џорданове криве каже да ће увек постојати ентеријер и екстеријер, али преостаје на нама да одлучимо који је који. За то нам треба концепт оријентације. Обично тачке многоугла наводимо у редоследу казаље ка на сату или супротно од казаљке на сату. Када то урадимо, многоугао са својим ентеријером се може дефинисати овако:
$$P(p_1, p_2, …, p_n) = \{ k_1p_1 + k_2p_2 + … + k_{n}p_{n} \ge 0 \mid \sum_{i=1}^{n} k_i = 1 \}$$
а то је заправо генерализација дефиницје дужи.
Пресек фигура постаје пресек скупова. Између фигура $A$ и $B$ постоји пресек ако
$A \cap B \neq \varnothing$. Ми не можемо тачно одредити ове пресеке јер се у
једној фигури налази бескончан број тачака. Уместо тога, користе се аналитичка
решења и векторске формуле како бисмо дошли до закључка.
Одређивање региона пресека између у општем случају није могуће (за многоуглове
кориситмо алгоритме исецања/клипинга), али то није проблем јер у физичким
симулацијама игара нас интересују само вектор нормале судара, дужина пројекције
судара на вектор нормале и коначан скуп тачака исецања (у 2D су обично довољне
$2$ тачке). Додуше, ова тема спада у уску фазу детекције судара, те се
заустављам овде.
Распричах се о метричким просторима, а остатак чланка се бави векторима,
стаблима и if-овима, па се поставља питање ,,чему све ово"? Хтео сам да
помогнем у стицању интуиције о томе како су настали ови алгоритми и структуре
података. Доста ових ствари могу да се визуализују а исправност ове
визуелизације зависи од разумевања првих принциа, а у овом чланку су то метрички
простори. Формализовањем ствари које се узимају као здраворазумске, можемо
елиминисати прављење скокова у логици. Размишљањем о томе шта се дешава уколико
неки облик постане бесконачно велик или мали, или шта ако се два облика
поставе бесконачно далеко, моћи ћете да цените зашто су претпоставке исправне,
или макар зашто се чине исправним.
Формулисање проблема
Нека је ентитет тип који представља објекат у дводимензионом еуклидовском простору и који има запремину већу од $0$. Две димензије сам одабрао ради једноставности. Имати запрамину већу од $0$ значи да ентитет има облик уместо да је бесконачно мала тачка. Појам запремине овде представља формализацију у $n$-димензионом простору, односно у нашем случају је то површина. Ентитети без запремине се зову честице и оне поједностављују ствари, али нису практичне у општем случају.
Задатак је одредити скуп парова ентитета $e_1, e_2$ чије се запремине секу. Ово скоро да личи на детекцију судара, али овде игноришемо брзине ентитета. Интересује нас само ово питање: који ентитети се тренутно секу?
У зависности од случаја коришћења, парови ентитета су уређени (двојке) или неуређени (бинарни скуп). Погони за игре обично користе неуређене парове јер нема потребе да се исти судар обрађује два пута. У овом чланку ћемо користити неуређене парове $\{e_1, e_2\}$.
Унапред знамо који парови ентитета могу бити у резултујућем скупу. Било који ентитет може да се упари са било којим другим ентитетом (осим са самим собом), стога ако имамо $n$ ентитета, укупан број могућих парова је $\binom{n}{2}$.
Важно је увести појам граничних оквира. Погледајте слику испод. Ако је сваки ентитет у сцени звезда, онда би проверање да ли се звезде секу подразумевао да постоји софистициран алгоритм за пресеке попут Separating Axis Test.

Прецизне провере пресека су део уске фазе у детекцији судара. Овај чланак се бави широком фазом. Није мудро користити алгоритме који раде са прецизним облицима. Можемо пре тога да уклонимо грешке првог реда (false positive) ако урадимо проверу између граничних оквира ентитета. Ови оквири су често веома примитивни, а њихова конструкција и провера судара је ефикасна.
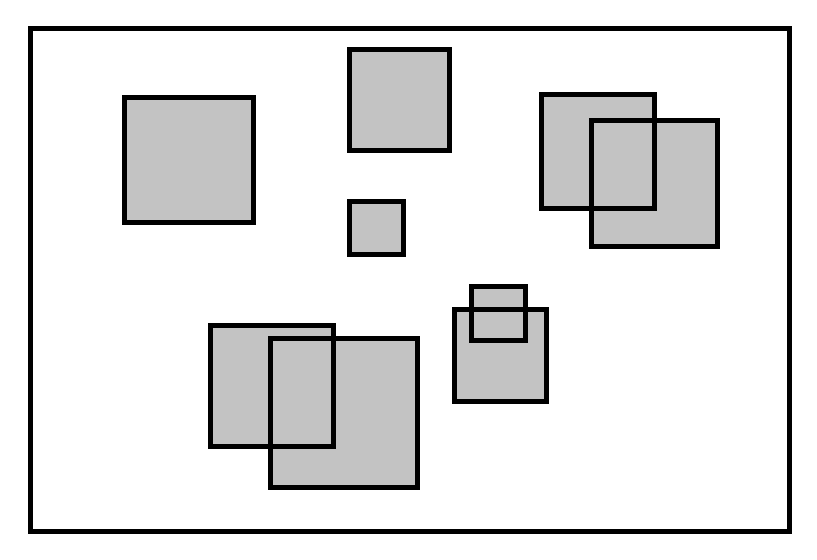
Правоугаоници уравнати са осом или кругови имају $O(1)$ алгоритам за пресецање, а њихова констуркција је $O(N)$ за $N$ тачака ентитетовог облика. Често можемо да израчунамо гранични оквир унапред и претпоставити да се он мења само када се ентитет скалира, ротира или ако се сама запремина ентитета деформише. Обично погони за игре не дозвољавају ову последњу ставку јер се претпоставља да су ентитети крута тела.
У овом чланку се користе правоугаоници уравнати са осом (axis-aligned rectangle) за ограничавајуће оквире. Кругови су погоднији код облика са сличном ширином и висином, а у супротном се могу користити елипсе. Међутим, стратегије о којима ћу причати у наставку углавном користе крајње ивице граничног оквира по $x$ или $y$ оси, те је природно одабрати правоугаонике.
Наивни приступ
Најпростије решење овог проблема је да се прође кроз све могуће парове ентитета и провери да ли се њихови ограничавајући оквири секу. Овај приступ се не скалири добро: обавићемо $\binom{n}{2}$ провера у $O(n^2)$ времену. Упркос томе, овакав brute force приступ може да се користи као основа за проверу тачности других стратегија.
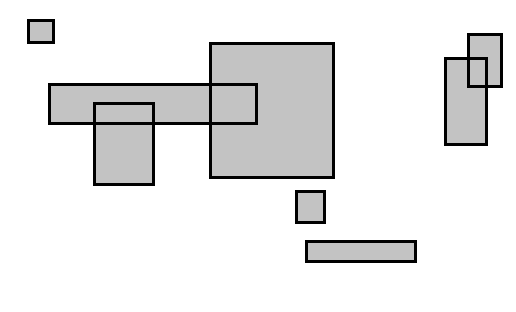
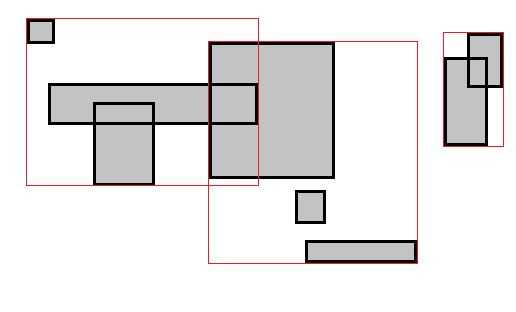
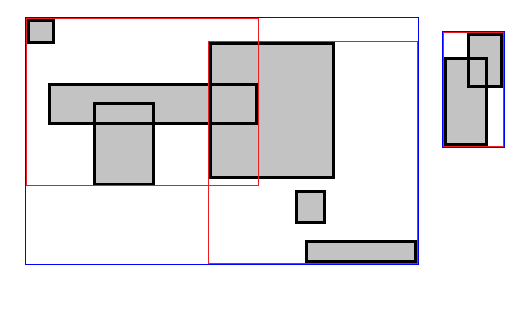
Да бисмо развили интуицију како да побољшамо ово, обратите пажњу на следећу слику. Примећујете ли како су правоугаоници постављени на такав начин да природно формирају два кластера?
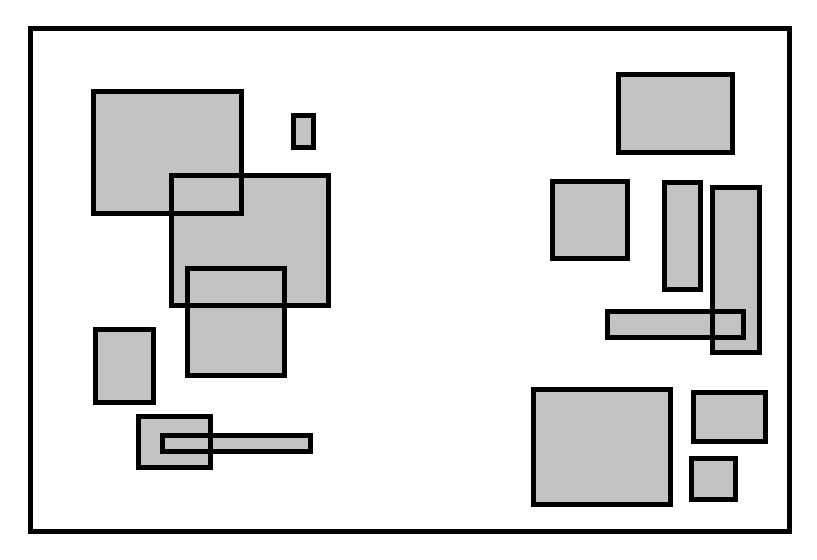
Изгледа очигледно да ниједан правоугаоник из левог кластера не може да се сече са било којим правоугаоником из десног кластера. Шта ако ова два кластера обрадимо засебно? У првом кластеру има $7$ правоугаоника а $8$ у другом. Поребно је $\binom{7}{2} + \binom{8}{2} = 49$ провера, у односу на претходних $\binom{15}{2} = 105$.
Да бисмо дошли до ових кластера, прво сортирамо правоугаонике по $x$ оси и повлачимо линију између два суседна правоугаоника са највећом удаљеношћу на $x$ оси. Понекад је боље делити по $y$ оси. Можемо одредити која је оса боља у линеарном времену тако што срачунамо варијансу на свакој оси. У идалном случају, овај приступ ће бити $n\log(n) + \frac{n^2}{2}$. То јесте $O(n^2)$, али погледајте следећи график:
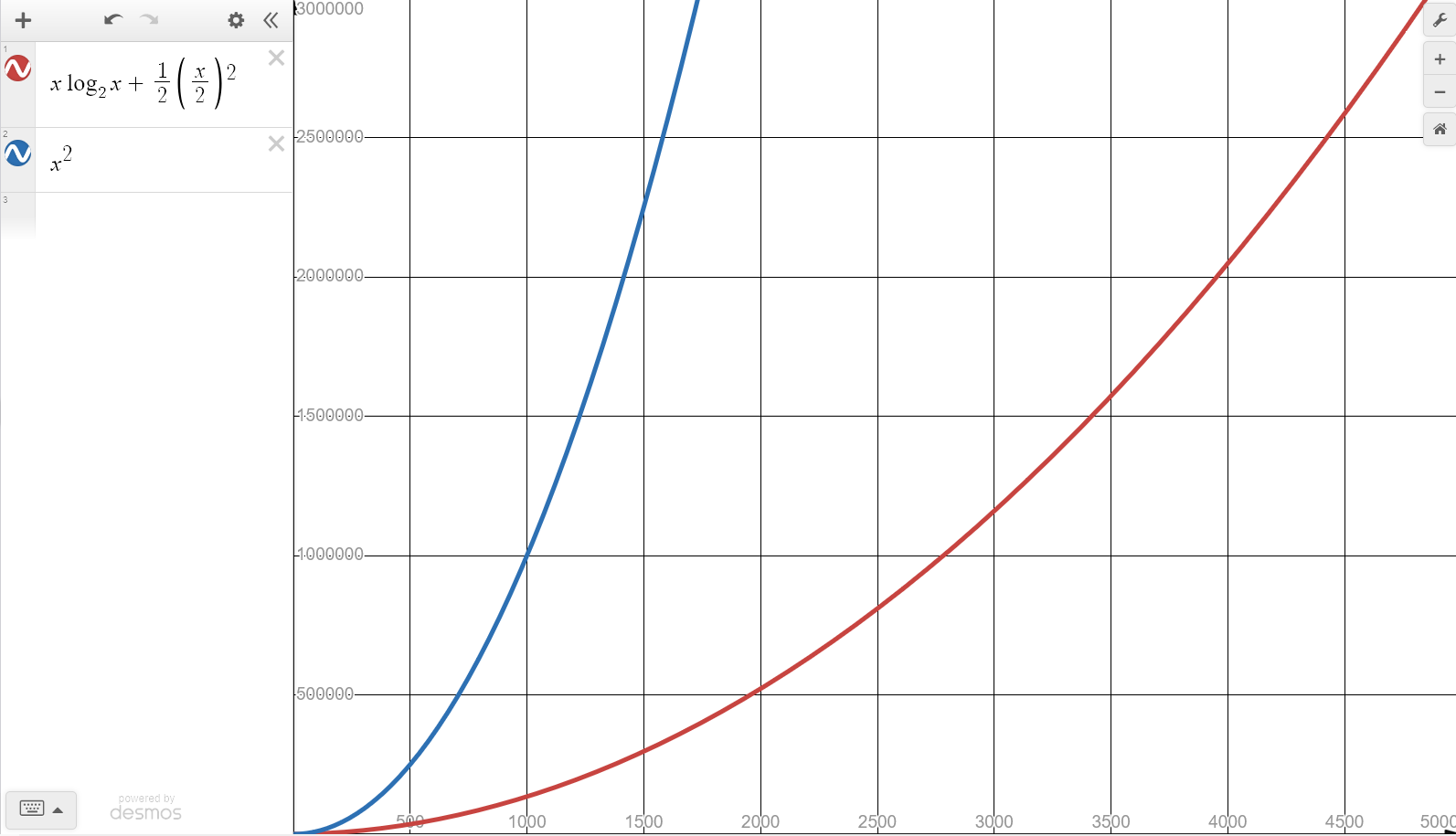
У реалистичном и практичном сценарију, број ентитета у игри неће бити ни близу бесконачности. Ако имамо $5000$ ентитета, уштедели бисмо отприлике $2 \cdot 10^7$ операција. То уопште није тривијална количина. Иако је $N=5000$ довољно добро за игре, ако скенирамо базу података са милионима ставки, ови добици опадају брзо. Не можемо увек одбацити теоријску границу зарад практичне границе. Штавише, овај приступ има два велика проблема.
- неће радити ако правоугаоници не формирају два дисјунктна кластера
- неће радити ако кластери нису балансирани
Ова два проблема могу да се елиминишу ако се определимо за паметнији и генералнији приступ у груписању потенцијалних кандидата.
Сортирај и исеци
Сортирај и исеци (sort and sweep, sweep and prune) је алгоритам за широку фазу детекције судара. Ради тако што сортира граничне оквире и одбацује (исеца) све кандидате за које је гарантовано да се не секу.
Прво ћу описати слабији алгоритам из којег се sweep and prune_ може извести. Основа алгоритма је иста. Прво, сортирамо објекте (односно граничне оквире) по једној оси. Ради илустрације нека то буде $x$ оса. Затим, за сваки објекат одредимо мању границу са леве и већу границу са десне стране граничног оквира. Све између те две границе је кандидат за судар са тим објектом. Звучи једноставно, али морамо пазити како сортирамо објекте и како одређујемо границе.
На пример, нека су дати објекти као у слици испид. Соритраћемо их по $x$ оси на основу неке модификоване фунцкије метрике $d^\prime : M \to \mathbb{R}$. У овом примеру сам одабрао $x$ коодринату леве ивице објекта. Испод свих објеката дата је бројевна права на којој су пројектоване леве ивице. Бројеви представљају редослед објеката, а не јединице на бројевној прави.
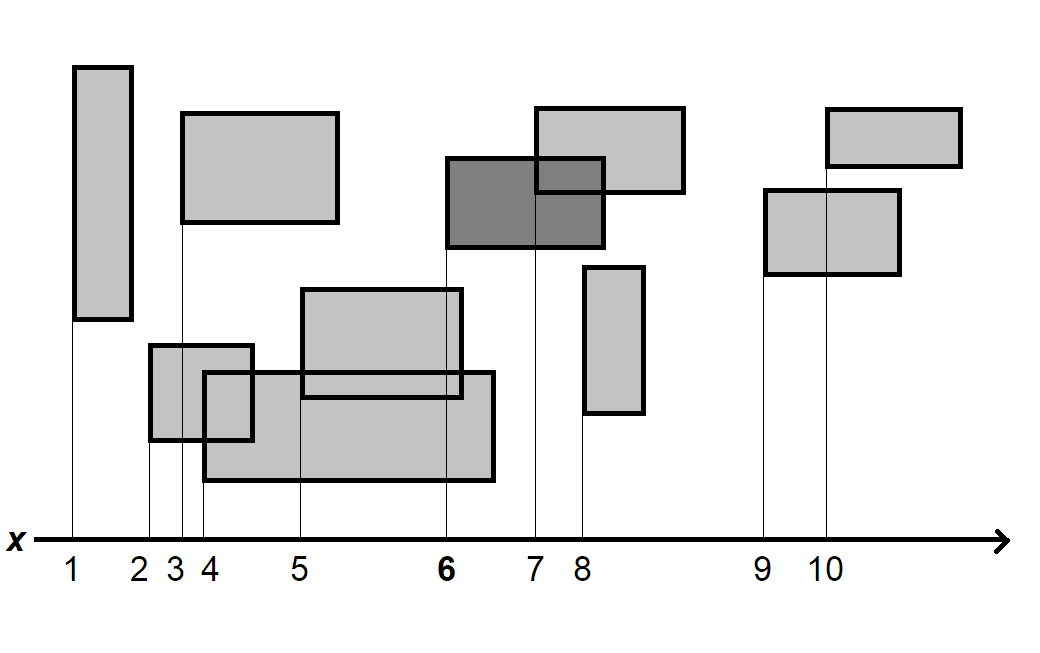
У другом делу алгоритма тражимо кандидате за сваки од објеката. Посматрамо шести објекат, означен на слици изнад. У brute force приступу, проверавали бисмо све остале објекте. Овог пута ћемо искористити чињеницу да су објекти сортирани по левој ивици.
Када сортирамо листу, успоставља се инваријанта: ако је број $k$ $i$-ти елемент у сортираној листи, онда сви елементи десно (на позицији $i+1, i+2, …, n$) су већи или једнаки од $k$, а сви елементи лево (позиције $i-1, i-2, …, 1$) су мањи или једнаки од $k$. Ова инваријанта служи као основа за бинарну претрагу и проналажење горње или доње границе.
Шта ће бити горња граница у намеш примеру? Биће први објекат чија је лева ивица већа од десне ивице шестог објекта, а то је објекат (9). Можемо користити бинарну претрагу да пронађемо тај објекат у $O(\log{n})$.
Шта је са доњном границом? Она ће бити први објекат чија је десна граница мања од леве границе шестог објекта, а то је објекат (3). Овог пута не можемо радити бинарну претрагу јер инваријана не важи за десну границу објеката. Имамо два избора: сортирамо објекте и по десној граници, или урадимо линеарну прертагу. Први приступ је зезнут, док је други $O(n)$.
Када пронађемо горњу и доњу границу, све између је кандидат средњу фазу колизије (где тражимо пресек између одабраних парова правоугаоника) и уску фазу (где користимо праве облике уместо граничних оквира). Време изувршавања овог псеудо-sweep and prune алгоритма је и даље $O(n^2)$, али у просечном случају даје боље перформансе од наивног приступа. Штавише, уколико претпоставимо временску кохерентност (више о томе у наставку), онда амортизовано време извршавања постаје $\mathcal{O}(n\log{n})$.
Сада ћемо се позабавити правим sweep and prune алгоритмом. Кључна идеја је да се објекти не сортирају по левој или десној ивици, него по обе ивице.
Хајде прво да решимо простији изоловани проблем. Нека је дат стринг s чији је
сваки карактер отворена угласта заграда [ или затворена угласта заграда ].
Интервал се јединствено дефинише са једном отвореном угластом заградом и једном
затвореном. Израчунај број пресека између свих интервала. На пример, ако је s = [[]][[][]][], онда постоји $3$ пресека.
Прво, уочимо да је решење јединствено ако је s правилно формиран. Чак и у
случајевима попут [[]] где имамо један мањи интервал уписан у већи интервал,
или два интервала једнаке величине који се секу, одговор је исти. Задатак се
решава помоћу стека. Скенирамо кроз стринг, на сваку појаву [ број пресека
повећавамо за величину стека и додајемо [ на стек. На сваку појаву ],
избацујемо горњи елемент са стека.
Надоградња на овај проблем захтева од нас да одредимо све пресеке. Интервали су
нумерисани $1, 2, 3, …$ а алгоритам треба да избаци листу парова $(i, j), i <
j$. Прво примећујемо да је неопходно да интервали буду нумерисани, јер у
супротном резултат није јединствен. И заиста, за улаз [[][]] имамо више
могућих решења: $\{(1,2), (1,3)\}, \{(1,2), (2,3)\}$. Зато ћемо
претпоставити да је улаз низ парова (char, int). Да бисмо решили овај проблем,
чувамо стек целих бројева који представљају све незатоврене интервале до сада, и
на сваком ('[', k) ћемо додати (k_i, k) у коначни резултат, где је k_i
$i$-ти елемент у стеку. Ово је оптимално решење за овај проблем и у најгорем
случају се изврашава у $O(n^2)$ времену, али у просечном случају је $O(n)$.
Sweep and prune генерализује овај приступ. Нека је ивица уређена тројка $(x, v, c) | x\in \mathbb{R}, v \in \mathbb{N}, c \in \{0,1\}$ која представља координату ивице $x$, јединствен идентификатор за оквир или објекта $v$ којем та ивица припада и Булову вредност $c$ која нам говори да ли је ивица ,,отварајућа" (нижа, лева; $0$) или ,,затварајућа" (виша, десна; $1$). Листу ивица формирамо пресликавајући сваки објекат у по две ове тројке. Потом сортирамо листу по $x$ и извршимо алгоритам како је описан изнад.
Погледати следећу слику. Овај пут не радимо проверу за сваки објекат понаособ, него редом пролазимо кроз листу и одједном генеришемо резултате.
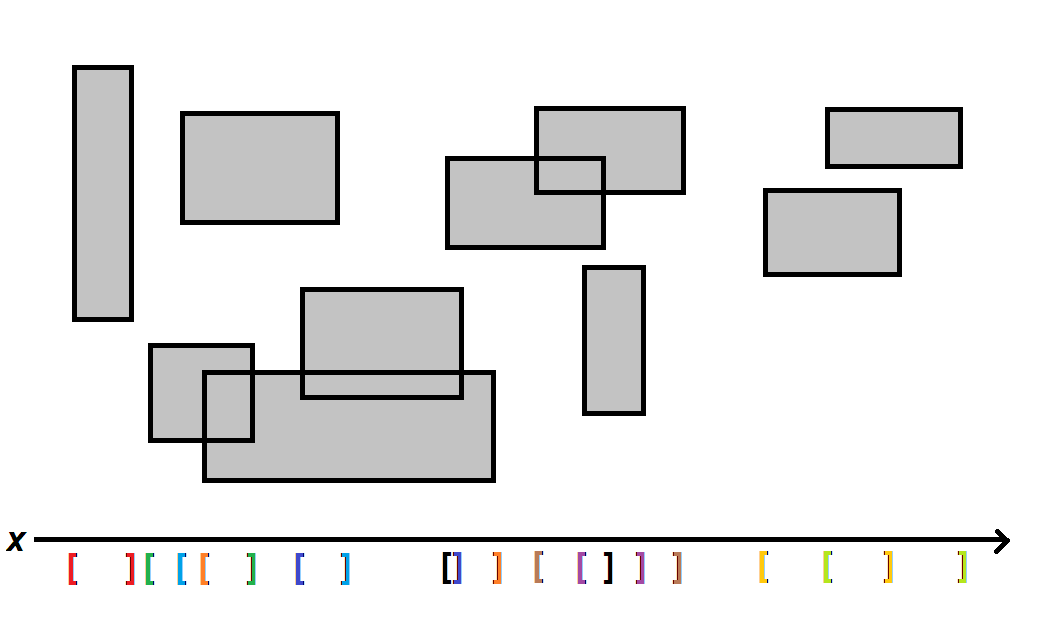
Ефикасност sweep and prune је $O(n\log{n} + k)$ где је $k$ највећи могућ број парова. У најгорем случају $k$ износи $\binom{n}{2}$, али најгори случај се скоро никад неће десити, и $k$ је обично $O(n)$, па се време извршавања може свести на отприлике $O(n\log{n})$. Ово би могло додатно да се убрза. Много процесног времена се троши на сортирању низа сваки пут кад се алгоритам изврши. Размислите о временској кохерентности: између два позива алгоритма (обично два суседна фрејма у игри), објекти се неће померити много јер су њихове брзиме углавном много мање од пречника њихових ограничавајућих оквира. Према томе, сортирана листа се такође неће много променити. Другим речима, можемо претпоставити да ће листа увек бити парцијално сортирана, и стога би требало да користимо адаптивни алгоритам за сортирање попут сортирања убацивањем (insertion sort) чије је време извршавања $O(n)$ за парцијално уређене низове. Не можемо увек да се ослањамо на ово, поготово на првом фрејму, али ако се може претпоставити временска кохерентност (што и јесте случај у већини игара), онда је амортизовано време за sweep and prune $\mathcal{O}(n)$.
Хеширање решетке
Важна особина облика у метричком простору $(M, d)$ је да се два облика сударају са већом вероватноћом што су међусобно ближи, или формалније:
$$ \lim_{d(A, B) \to 0} P(A \cap B \neq \varnothing) = 1 $$
Ово важи само за конвексне случајеве (замисли круг који се налази у рупи крофне и како у том случају не важи), али ми овде говоримо о правоугаоницима те ова особина важи. Ово је битно јер то значи да би кандидати за судар барем требало да буду објекти који су природно близу један другом. Међутим, није довољно да се буквално ослањамо на ову особину: замисли правоугаоник са бескончаном дужином бесконачно удаљен од неког референтног правоугаоника. Морамо посматрати не само центар облика, већ и ивичне тачке. За AABB правоугаонике, постојаће $4$ тачке по облику.
Хеширање решетек дели простор у униформну решетку (мрежу, grid) где је свака ћелија бакет (bucket, кофа). За правоугаоник $R$, убацићемо $R$ у сваки бакет у чијој ћелији се налази барем једна од тачака из $R$. Судар се може десити само између правоугаоника у истом бакету. Погледајте следећу слику:
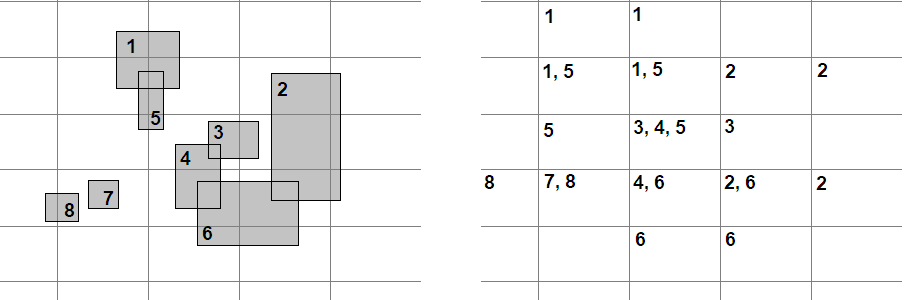
Са леве стране видимо решетку и $8$ правоугаоника (сваки од њих је означен). Са десне стране приказана је решетка и у свакој од ћелија низ бројева који представљају ознаке правоугаоника који припадају тој ћелији. За сваку ћелију ћемо одредити судар само са правоугаоницима који се налазе у бакету те ћелије.
Колико је убрзање? За почетак знамо да наивни приступ подразумева $\binom{8}{2} = 28$ провера, док у овом случају имамо само $8$. Штавише, пошто не дозвољавамо дупликате у сударима, биће укупно $7$ провера.
Хеширање решетке може се имплементирати користећи хеш табеле или плочице. Хеш табеле су флексибилније али може доћи до колизије између хешева па су и спорије. Добра хеш функција би била $h(x, y) = x * p_1 \oplus y * p_2 \mod n$ где су $p_1$ и $p_2$ прости бројеви а $n$ је величина хеш табеле; или бисмо уместо тога користили Мортонову бесконачно густо криву. Плочице имају фиксан распон али је хеширање прецизно и брзо јер су плочице репрезентоване као 2D матрица.
Да ли сте приметили проблем у овом приступу? Погледајте поново слику изнад, и то правоугаоник $2$, и размислите како би он прескочио одређене сударе. Ево јаснијег примера:
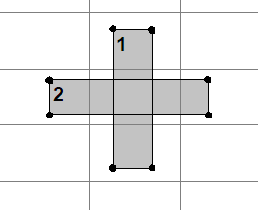
Облик који се простире кроз више од две ћелије решетке неће бити убројен у бакете свих међућелија. У слици изнад, правоугаоници $1$ и $2$ се секу у средишњој ћелији, али ниједан од њих нема крајњу тачку у тој ћелији, па губимо информацију.
Величина ћелије је хиперпараметар, и хеширање решетке функционише само ако су сви облици мањи од ћелије (у обе осе). Ако унапред знамо да постоји максимална величина граничних оквира, ово није проблем. Ако не знамо, можемо скенирати кроз све објекте и унапред одредити који је највећи. Ово је у реду, но ако не постоји горња граница за величине објеката, онда величина ћелије може расти неодређено што доводи до опадања у добицима на перформансама.
Потребан нам је адаптивни приступ где величина ћелије није униформна. Да бисмо то постигли, метрички простор морамо представити на хијерархијски начин, и за то ћемо користити стабла.
Квадратно стабло
Квадратно стабло је просторна структура података за сегментацију 2D простора. У 3D простору аналог је окално стабло, и оно функционише на исти начин.
Чвор у квадратном стаблу је правоугаоник који обухвата површину у простору. Објекте се додају у чвор све док се капацитет тог чвора не прекорачи. Кад се то деси, чвор се дели на 4 детета, и сваки објекат у чвору се шаље у оно дете чију површину сече тај објекта. Процес се понавља рекурзивно, или све док чвор не достигне одређену минималну величину након које дељење више није могуће. Листови квадратног стабла су бакети у којима се налазе кандидати за судар.
Слика испод илуструје квадратно стабло. Са леве стране је приказан мерљив простор и сви гранични оквири објеката. Објектима је додељена означа од $1$ до $7$. Нацртана је решетка која представља издељено квадратно стабло. Са десне стране је илустрована структура самог квадратног стабла. Препостављамо да је капацитет чвора $2$. На врху стабла се налази коренски чвор, и он покрива читав простор. Пошто постоји $7 > 2$ објеката у коренском чвору, долази до дељења, и свакко дете (горње лево, горње десно, доње лево, доње десно) узима $1/4$ површине родитељског чвора. Листови су осенчени а ознаке објеката који покривају лист су написани испод њега. Доње десно дете корена се такође дели.
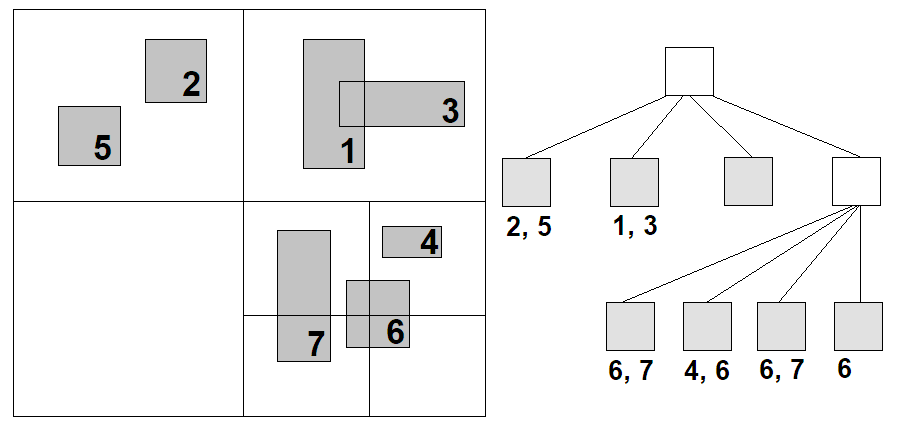
Обавиће се $5$ проверва свеукупно ($4$ ако се дупликати не рачунају), за разлику од brute force решења где би било $21$ поређење. Колико добро ће квадратно стабло да ради зависи од хиперпараметра капацитета. Инуитивно бисмо желели да то буде вредност $c$ која максимизује добитак у перформансама $n^2 - \frac{n}{c} c^2$ а минимизује потребан рад $\frac{n}{c} c^2 = nc$.
Квадратна стабла се добро адаптирају на случајеве где имамо локалне кластере
објеката и доста празног простора између тих кластера. Меморијско заузеће тог
празног простора је минимално.
У односу на хеширање решетака, квадратна стабла немају проблем са објектима који
се простиру крзо више од две ћелије (односно чвора) у било ком правцу, јер се
овде дешава инверзија контроле: у хеширању решетке, објекат одређује којем
бакету припада; у квадратном стаблу, чворови су они који одлучују који објекти
припадају њиховом бакету.
Нажалост, квадратна стабла имају и своје недостатке.
(1) Прво, ова структура је дизајнирана за честице (немају облик). Приметите како
се у горњој слици један објекат налази у више бакета. Ова ситуација може да
доведе до ситуација где се стабло дегенерише у наивни приступ, мада је ово
реткост. Ипак, дупликати су веома чести и доводе са собом деградацију
перформанси током конструкције стабла пошто је вероватноћа дељења чвора
повећава.
(2) Друго, претходно описани хиперпараметар капацитета $c$ је пресудан за
оптимизацију у широкој фази. Ако ваша игра гарантује разумну расподелу елемената
у простору, $c$ се може лако израчунати. Ако су објекти велики а $c$ је мало,
брзо ће се конструисати комплетно стабло максималне висине. Када се то деси,
квадратно стабло се понаша као хеширање решетке, са додатним утрошком времена на
конструисању стабла.
(3) Трећа, ви морате унапред навести величину простора. Ово можда не звучи као
велик проблем, поготово јер се те границе могу одредити у $O(n)$ времену у
сваком фрејму, али у тада није могуће применити икакву паметну оптимизацију $c$
хиперпараметра. И не само то, него је неопходно да одредите и минималну
дозвољену величину чвора за коју није дозвољено даље исецање.
Хајде да размислимо откуд су се појавили ови проблеми са квадратним стаблима. Ви узимате комад простора и делите га на решетку неједнаке величине. Захтевате да сви објекти буду у овој решетци без озбира на њихову позицију. Конструисање квадратног стабла нам изгледа досетљиво јер ни у једном тренутку стабло не мора да размишља о томе којем чвору да пренесе објекат, већ се све своди на “прешао си ову линију, тако да ћеш барем бити овде”. Стабло се конструише на основу простора које је константно, уместо на основу објеката, чије су позиције и облици променљиви.
Квадратна стабла оптимизују погрешну меру: густину објеката у јединици простора. Уместо тога, стабла би требало да одреде свој облик и структуру на основу природних мера објеката, и то је управо оно што раде R-стабла.
R-стабло
R-стабло је стабло чији чвор има највише $B$ деце ($B$ је хиперпараметар). Сваки чвор представља површински сегмент простора, и ти сегменти могу да се секу (могу да се секу и у квадратним стаблима, али само у виду ,,дете се налази унутар родитеља"). R-стабла могу да покрију произвољни простор, а чворови ће увек покрити само онолико простора колико им треба, никад више.
Принцип R-стабла је сличан квадратном стаблу: убаци објекат у чвор, подели чвор када број објеката пређе капацитет. За разлику од квадратног стабла, чвор у R-стаблу се дели неједнако, у циљу да чворови наследници буду што мањи.
Чвор у R-стаблу се дели тако да се оптимизује нека мера, и најчешће се макимизује неискоришћен простор:
$$ \argmax_{N_1, N_2} Area(N \setminus (N_1 \cup N2)) $$
Погледајте слику испод. Са леве стране се налази R-чвор (уоквирен црвеном бојом) у којем се налази $5$ објеката. На десној страни су приказане две поделе, означене редом $A$ и $B$, и њихови оквири су обојени плавом бојом. У овом примеру, подела $A$ доноси већа неискоришћена површина.
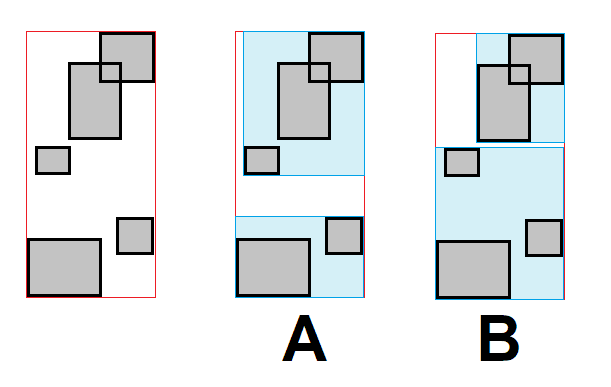
Интуиција око овога је да већа неискоришћена површина даје компактније граничне
оквире за два нова чвора. Ако су нека два објекта јако далеко, онда је
неискоришћена површина између њих већа. Већ смо установили да верованоћа пресека
опада како се објекти удаљују. Погледајте слику испод, подела $A$ није природна
и доводи до трошења рачунског времена на случајеве који су видљиво очигледно
негативни.
Још једна ствар коју би требало да споменем јесте да можемо да
максимизујемо/минимизујемо обиме правоугаоника уместо њихових површина. Замисли
танак али јако дугачак правоугаоник. Његова површина није велика, али удаљеност
дуж дуже осе је велика, те ће алгоритам урадити поделу тако да се објекти не
могу сећи.
Одређивање површине уније дводимензионих правоугаоника је Клијов проблем мере за
случај $d=2$ и он се може решити користећи Бентлијев алгоритам у $O(n\log{n})$.
Штавише, може се показати да за $d=2$, доња граница решења је
$\Omega(n\log{n})$.
У општем случају постоји $2^{n-1}-1$ начина да се подели чвор у R-стаблу који
има $n$ елемената, где се сваки објекат може ставити у један или оба чвора (оба
јер се површине чворова могу пресећи).
Према томе, горња граница за одређивање оптималне поделе је $O(2^{n}n\log{n})$
што није практично за реалне случајеве коришћења.
Да бисмо побољшали ово, морамо увести апроксимације и хеуристике. Ове оптимизације се често заснивају на одабиру два базична објекта за референтну основу преосталих човорва, и онда се они проширују за преостале чворове један п оједан на основу хеуристике минималног увећања површине при убацивању објекта $o$:
$$\argmin_{i \in \{1, 2\}} Area(N_i \cup o) $$
У оригиналном раду о R-стаблима су споменуте три такве поделе:
- Линеарна подела: На свакој оси се одређују два објекта са највећом удаљеношћу на тој оси. Та дв аобјекта су базична. Преостали објекти се похлепно убацују у онај базични објекат који доводи до мањег увећања површине. Време извршавања је $O(nd)$ у $d$ димензија.
- Квадратна подела: Траже се два објекта са највећим неискоришћеним простором:
$Area(N_i \cup N_j) - Area(N_i) - Area(N_j)$. Ти објекти су базични. Поступак се наставља као у линеарној подели. Време извршавања је $O(n^2)$. - Експоненцијална подела: Као квадратна подела, али свих $O(2^n)$ комбинација се проверава.
Главни проблем са овим апроксимацијама је што уводе пресецање између чворова, а то доводи до деградације у перформансама. Уско грло R-стабала није конструкција, већ спровођење упита. Генерално би било боље да се одабере квадратна подела која јесте скупља за креирање али зато умањује грешке првог реда.
И квадратна и линеарна подела доводе до превеликог пресецања. Постоје варијације
R-стабла осмишљене да се ово ублажи. На пример, R*-стабло тежи да умањи површину
између чворова, а површину и укупно пресецање између чворова са истим родитељем.
Осим тога, ово стабло покушава да избегне дељење чворова кад год је то могуће
тако што узме $f \in [0, 1]$ (обично $~30\%$) најудаљенијихи објеката од центра
чвора и поново их убаци у стабло почевши од корена. Ова идеја је инспирисана од
технике балансирања B-стабла. R*-стабла су скупља за конструкцију, али она то
надокнађују кроз боље амортизовано време при упитима због умањеног пресецања.
Нажалост, R*-стабла се понашају лоше када имамо густо збијене објекте у маленом
простору. Пошто R-стабло није јединствено (осим у случају да користимо оптимални
приступ при дељењу чворова што није практично), редослед у којем се објекти
убацују у стабло може итекако да утиче на перформансе.
R-стабло учитано одједном
Пошто унапред знамо улазне податке, можемо искористити одређене механизме учитавања одједном како бисмо прерадили објекте на такав начин да стабло буде оптимизованије.
У овим механизмима градимо стабло од доле ка горе, што олакшава конструкцију
R-стабла јер не морамо да делимо чворове и поново убацујемо објекте како би
стабло било балансирано, нити морамо рачунати скупе хеуристике да бисмо смањили
пресецање између чворова.
Генерална идеја иза свих ових механизама је иста: листови се граде на основу
објеката који су локално близу (на основу метрике удаљености $d$), чворови на
вишим нивоима се формирају на основу истих хеуристика, процес се понавља
рекурзивно све док не добијемо ниво на којем је један чвор - корен. Хеуристика
ће у овом случају бити функција поретка на основу које се објекти сортирају.
Најближи-X је једноставан алгоритам који сортира објекте по $x$ и групише их у сегменте величине $k$. Нови R-чвор обухвата једну такву групу. Процес се понавља а $k$ се смањује у сваком наредном нивоу стабла.
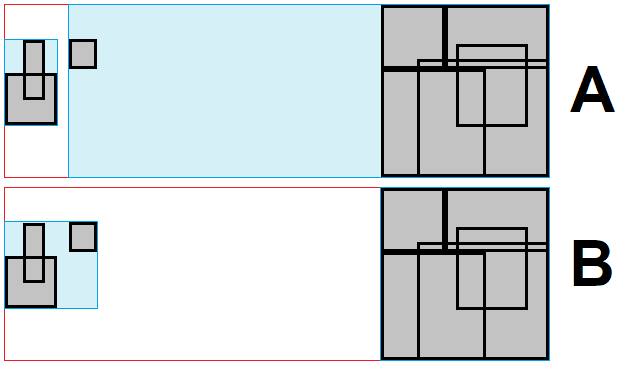
Посматрајмо следећи пример. Имамо сцену са $n=8$ објеката у њој, и одредили смо капацитет $k=3$ (горње лева слика). Престпоставимо да су објекти сортирано по $x$ координати њиховог центроида. Прва $k=3$ објеката ће бити груписано у први лист, наредна $3$ објекта у други и преостала $2$ објекта у трећи лист (горње десна слика, листови су приказани као правоугаоници). Имамо $3$ листа у горњем нивоу досад-изграђеног стабла, те настављамо са алгоритмом. Сада је $n=3$ а $k=\max\{\frac{n}{k}, 2\}=2$ ($k$ не сме бити $1$ да не бисмо упали у бесконачну рекурзију). Прва два листа се групишу у први нови чвор, а последњи лист у други чвор (доње лева слика, нови чворови су означени плавом бојом). Имамо $2$ чвора у горњем нивоу досад-изграђеног стабла, па настављамо. $n=2$ и $k=2$. Два ,,плава" чвора се групишу заједно у један чвор на новом слоју (доње десна слика, нови чвор је црне боје). Имамо $1$ чвор у горњем нивоу досад-изграђеног стабла, те он мора бити корен и стога се алгоритам завршава.
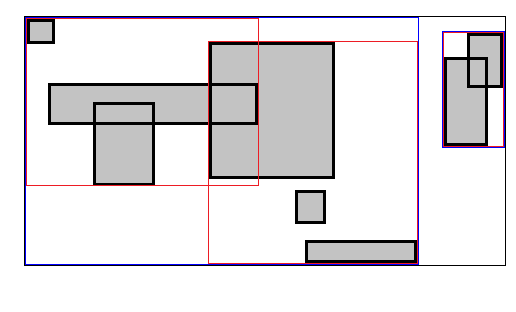
Чворове не морамо сортирати. Ако су објекти сортирани по центроиду, онда ће и сви чворови који их обухватају, а који се овде ефектнивно понашају као копнвексни омотачи, такође бити уређени по центроиду. Укупна временска сложеност је $O(n\log{n}+nd)$, где $d\approx \log_k{n}$ је дубина стабла.
Најближи-X добро ради у општем случају, али његове перформансе зависе од дистрибуције објеката по $x$ оси. Сортирање по $x$ оси ће углавном резултовати у стабло где је сваки чвор узак али висок. Иако компактност побољшава перформансе, велики обим сваког чвора редукује перформансе при упитима региона. Осим тога, дегенеративни случај је када су сви центроиди објеката на $x$ оси једнаки. Можемо ово заобићи ако прво одредимо осу са већом варијансом и сортирање обавимо на тој оси.
Sort-Tile-Recursive надограђује Најближи-X тако што покушава групише објеке и на $y$ оси. Док Најближи-X сортира објекте само по $x$ оси, Sort-Tile-Recursive користи напреднији приступ:
- Сортирај објекте по $x$ оси.
- За сваки део величине $\lceil \sqrt{n/k} \rceil$, сортирај објекте по $y$ оси.
Идеја је да сортирамо објекте и по $x$ и по $y$ оси у исто време, али пошто не постоји природни поредак дводимензионих података, другу осу апроксимирамо. Оно што добијамо овде је ефективно груписање објеката у решетку.
Погледајте слику испод за пример ($n=16, k=5$). У горње левој слици, правоугаоници су сортирано по центроиду на $x$ оси и означени. Сортирана листа се групише у делове величине $\lceil \sqrt{16/5} \rceil = 2$ као што је приказано у горње десној слици, а делови су представљени бојом објеката које покривају. Објекти у сваком делу се потом сортирају на $y$ оси и нове ознаке им се додељују, што се види у доње левој слици. Коначно, групишемо објекте у $k$ сегмената као што смо то радили у Најближи-X, и добијамо чворове који су приказани у доње десној слици ($A, B, C, D$). Алгоритам се понавља (направи $\lceil \sqrt{4/5} \rceil$ делова, групиши у $k$ итд.) док не дођемо до коренског чвора.
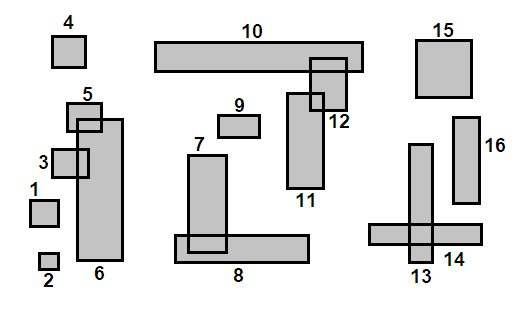
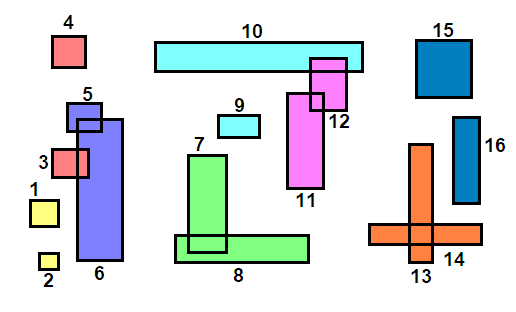
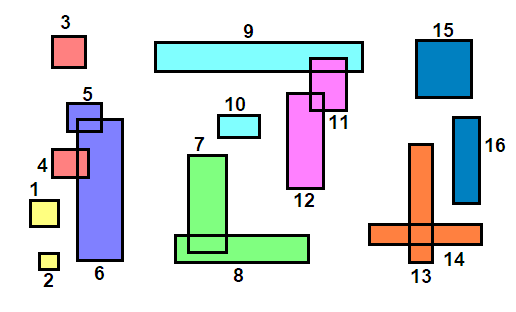
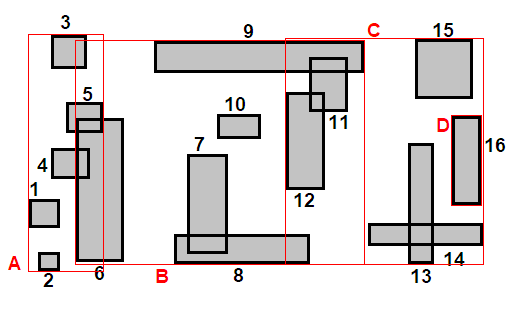
Ово је боље, али алгоритам и даље преферира $x$ дистрибуцију због начина на који функција соритрања пореди правоугаонике. Ако бисмо могли да смислимо хеуристику $f : \mathbb{R}^2 \to \mathbb{R}$ која једнако вреднује обе осе, елиминисали бисмо овај проблем.
Бесконачно густе криве
Још мало математике. Већ сам описао да је метрички простор скуп објеката којем је придружена функција удаљености. Та идеја ,,скуп са неким операцијама" се зове алгебарска структура и њима се бави апстрактна алгебра. Друге алгебарске структуре су групе, поља, прстени, решетке (lattices) итд.
Метрички простори су специјални, јер они нису чисте алгебарске стркутуре,
пошто је њихова неалгебарска структура позајмљена из топологије. Еуклидовски 2D
метрички простор је изоморфан векторском простору комплексних бројева
$\mathbb{C}$. То просто значи да одређена својства комплексних бројева такође
важе и у 2D еуклидовском простору.
Тачније, не постоји потпуни поредак у $\mathbb{C}$, односно комплексни бројеви
не могу да се поређају без да не дође до контрадикција када се пореде суме и
производи комплексних бројева. Еуклидовски 2D метрички простор такође нема
потпуни поредак јер не би био компатибилан са топологијом метричког простори.
Објаснити зашто је то тако је мало зезнуто, али поједностављена верзија приче је
да било које уређење 2D бројева не производи простор који је компатибилан са
еуклидовским 2D простором (комшилук елемента неће бити лоптастог облика).
Најближи-X и Sort-Tile-Recursive производе нееуклидовску топологију, и стога ови алгоритми имају мане. Срж тог проблема, као што рекох, је пристрасност према једној оси. Шта би било када бисмо могло да поређамо тачке у простору на тај начин да обе осе доприносе једнако у поретку?
У то долазе бесконачно густе криве (space filling curves). Бесконачно густа крива је функција која мапира јединични интервал на јединичну $n$-димензиону коцку:
$$ f : [0, 1] \to [0, 1]^n $$
Замислите да вам је дат задатак да нацртате изломљену линију из доње левог ћошка папира до горње десног ћошка папира, покривши читав папир, без подизања оловке са папира. Визуелно посматрано, бесконачно густа крива би пресликала ваш напредак где је $f(0)$ тачка у тренутку када почињете, а $f(1)$ тачка у којој се завршавате.
Многе бесконачно густе криве су фрактали, попут Пеано криве (лево) и Хилбертове криве (десно). Та особина нам је корисна јер се функције онда могу изразити рекурзивно и кроз итерације. Ове две слике доле нису праве Пеано и Хилбертове криве, јер не испуњавају читав простор у потпуности. Оне су 3. итерација својих крива. Свака наредна итерација додатно попуњава простор, и зато када $\text{iter} \to \infty$, крива ће заиста попунити читав простор на јединичном квадрату.

Зашто је ово битно? Јер ће инверзија функција бесконачно густе криве пресликати тачке у простору на реални број, и тиме добијамо поредак.
$$ f^{-1} : [0, 1]^n \to [0, 1] $$
Поредак и даље није потпун, али нема више пристрасности према иједној оси. Ако бисмо могли да сортирамо наше правоугаонике користећи инверзну бесконачно густу криву, онда бисмо побољшали претходна R-стабла учитана одједном.
Хилбертово R-стабло
Хилбертово R-стабло је механизам учитавања R-стабла одједном, сличан Најближем-X и Sort-Tile-Recursive. Правоугаоници се сортирају на основу Хилбертове вредности (вредност инверзне функције Хилбертове бесконачно густе криве) њихових центроида. Остатак алгоритма функционише исто као у Најближем-X.
Пошто су бесконачно густе криве непрекидне, не можемо их прецизно представити у рачунарима. Функција која рачуна Хилбертову вредност тачке у 2D простору апроксимира праву вредност. У том случају, простор се заправо дели на имагинарну решетку, а Хилбертова вредност тачке је индекс ћелије решетке у којој је тачка садржана, с тим да су ћелије поређане по шаблону Хилбертове криве.
Резултат није реалан број у $[0, 1]$, већ цео број у $[0, 2^{2k}]$ где је $k$ прецизност апроксимиране Хилбертове криве. Овај параметар обично има вредност $32$ или $64$, јер се алгоритам за рачунање Хилбертове вредности своди на манипулацију битова. Све тачке у метричком простору морају бити у распону $[0, 2^k)$ у обе осе, и стога се простор мора унапред скалирати.
Резултујуће Хилбертово R-стабло обично изгледа као хијерархија неуниформних ћелија решетке. Овде се надовезујемо на раније где смо причали о недостацима хеширања решетке. Комплексност конструкције Хилбертовог R-стабла је $O(n\log{n}+nd+nk)$, јер сваки правоугаоник се тачно једном пресликава на Хилбертову вредност у $O(k)$ времену (Шварцова трансформација).
K-d стабло
У секцији где је описан наивни приступ, укратко сам споменуо идеју да се простор подели у два подрегиона чиме смо успели да смањимо број провера. Ова метода поделе је кренула од претпоставке да постоје два дисјунктна кластера правоугаоника, што није увек случај. Иако то није било практично решење, идеја да се регион дели на два дела би могао да се искористи на другачији начин.
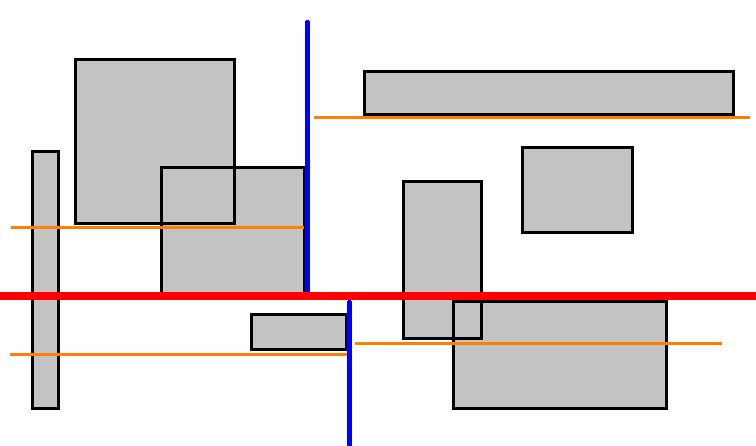
Ако поделимо низ правоугаоника по њиховом медијалном елементу (медијана правоугаоника сортираних на једној оси), онда бисмо могли лако да одбацимо половину елеманата када радимо упит за било који правоугаоник. На пример, хајде да сортирамо правоугаонике на основу њихове десне ивице и повучемо линију кроз медијану:
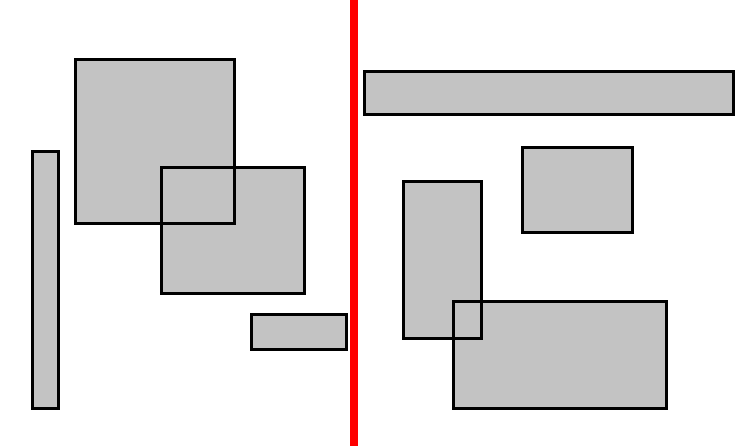
Да бисмо урадили упит за неки правоугаоник, морамо одредити како да одбацимо једну од две стране. Могли бисмо поредити десну ивицу упитног правоугаоника $r$: ако се налази са леве стране медијане $m$, онда се и лева ивица од $r$ налази са леве стране, тако да можемо одбацити десну страну поделе (све правоугаонике са десне стране $m$). Нећемо увек моћи да одбацимо десну страну, али моћи ћемо понекад.
Хајде да се не заустављамо овде, већ да поделимо ова два подрегиона на исти начин.
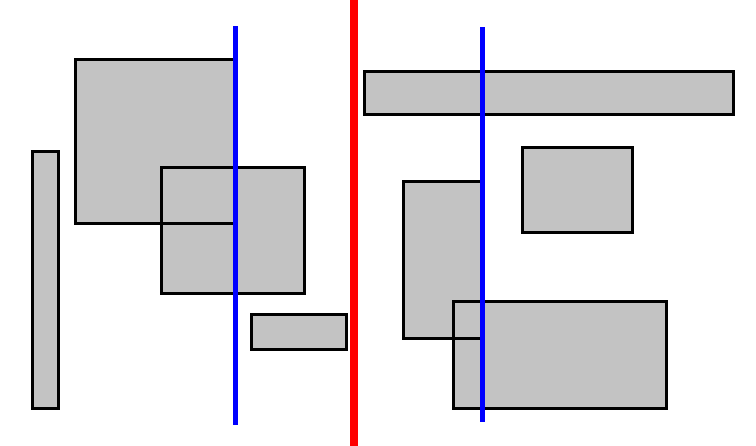
Овог пута неки правоугаоници секу медијану, и због тога не може увек засигурно знати да ли се једна од две стране може одбацити при обављању упита. Настављамо овај процес све док нам не остане $1$ правоугаоник у подрегиону.
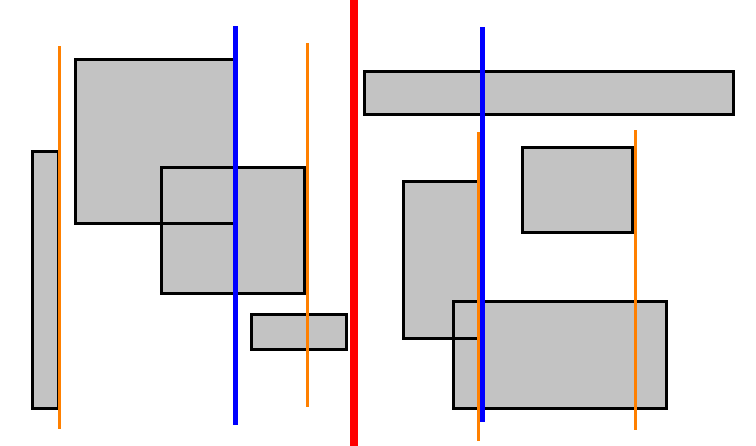
Добили смо бинарно стабло претраге са карактеристикама налик интервалним стаблима и сегментним стаблима. Мана у овом приступу је опет у томе што стабло фаворизује $x$ осу. Много боље би било да се оса наизменично мења: $(x, y, x, y, …)$ тако да сваки $2i$-ти ниво стабла користи $x$ осу, а $2i + 1$-ти ниво стабла користи $y$ осу за сортирање и дељење дуж медијане. Такво стабло се зове k-d стабло.
На слици испод приказано је како би k-d стабло изгледало за претходни пример. Медијалне линије су редом: црвена, плава, наранџаста. Оријентација линије се мења наизменично. K-d стабла нису у потпуности непристрасна, јер структура стабла зависи од осе на најнижем нивоу. На десној слици осе су обрнуте тако да се креће од $y$ осе.
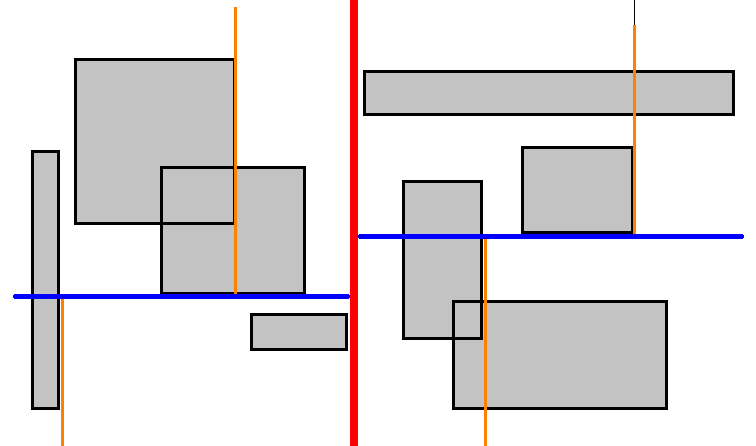
Иако би се k-d стабло могло градити све док листови немају један елемент, таква стабла би била сувише дубока и упити би трајали предуго. Уводи се хиперпараметар капацитета $c$ који би требало да буде барем $2^k$ где је $k$ број димензија у $k$-d стаблу.
Изградња k-d стабла се врши у $O(n\log{n}\log{n})$. Ако се објекти унапред сортирају на свакој од $k$ оса, ово се може свести на $O(kn\log{n})$. Уколико се користе бољи алгоритми за проналажење медијане (без сортирања низа), конструкција стабла се може додатно спустити на $O(n\log{n})$. Упит једног правоугаоника, у најгорем случају, је $О(n)$ док је у идеалном случају $O(\log{n} + c)$.
Бенчмаркинг
Алгоритмима и структурама података описаних изнад су тестиране перформансе користећи следеће параметре:
- алгоритам
- број ентитета
- постава ентитета
Вредности броја ентитета (односно $n$) су одабране како би се показала деградација перформансе али и уочили необични случајеви за мало $n$ (на пример, $n^2$ се понаша боље од $100n$ за мало $n$ али не и у општем случају).
Начин како се ентитети постављају, да ли су поређани по неком шаблону, груписани у кластере, колико је униформна њихова расподела итд. нам је помогла да стекнемо интуицију иза коришћења стабала и разних хеуристика. У бенчмаркингу је такође битан начин постављања ентитета, јер одређени алгоритми и структуре података раде под претпоставкама заснованим на претходно описаним опсервацијама.
- Random - случајна постава ентитета користећи униформну расподелу
- RandomLargeBoxes - као изнад, али ентитети су за ред величине већи па је пресецање чешће
- XLine - ентитети су постављени дуж праве чији је центар $x=c, c=const.$, и имају велику варијансу у дужини
- YLine - ентитети су постављени дуж праве чији је центар $y=c, c=const.$, и имају велику варијансу у ширини
- TrueUniform - ентитети су постављени униформно кроз правоугаону решетку, али њихова величина је малко већа од ћелије решетке како би постојао пресек
Резултати
Испод су резултати стандардног бенчмарка где је мерено укупно време једног фрејма у милисекундама. Референтне вредности које нас занимају су $33ms$ за $30$ FPS и $16ms$ за $60$ FPS.
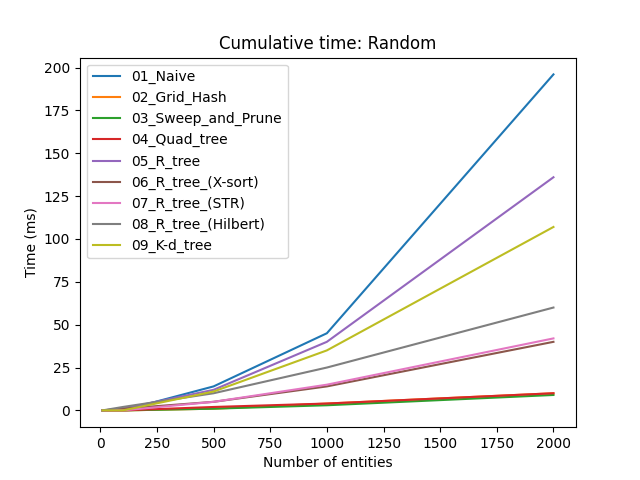
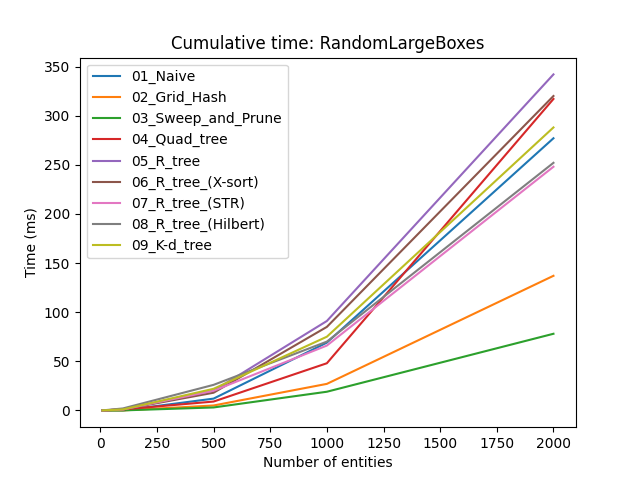
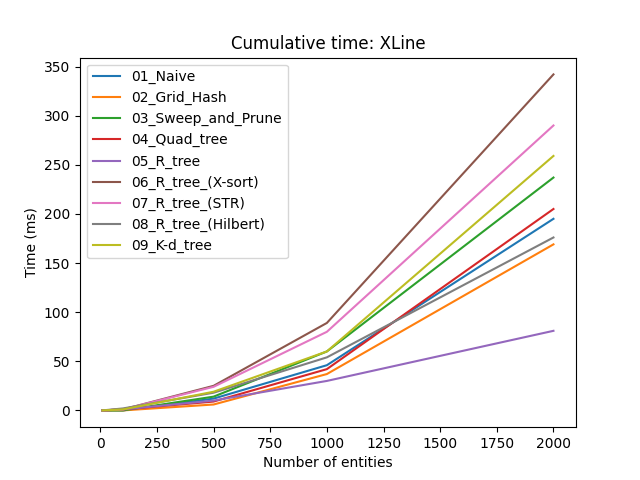
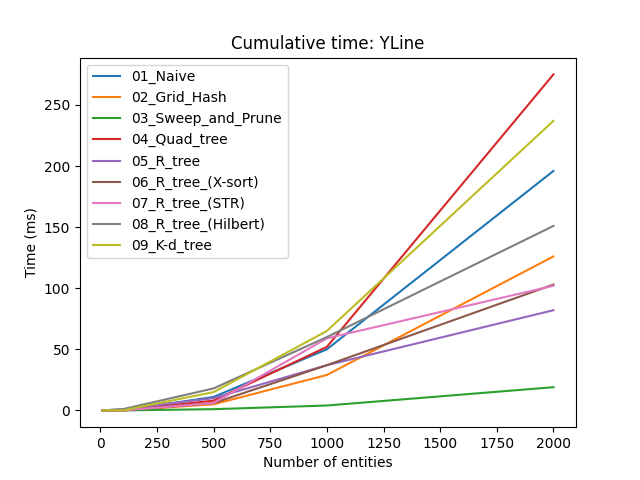
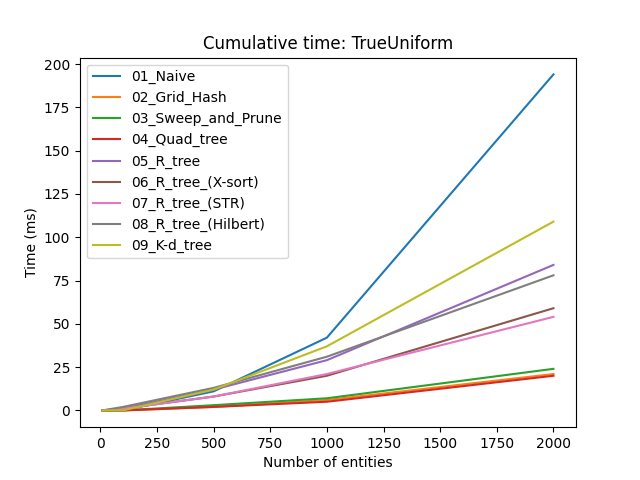
Прво што уочавамо је да за $n < 500$, избор стратегије није толико битан. Ако се свет игре може поделити у мање собе такве да се у било ком тренутку само у једној соби проверавају судари, вероватно можете заобићи употребу широке фазе.
Наравно, нас занима како се криве понашају када $n \to \infty$. Занимљива ствар (мада не толико изненађујућа) је да сортирај и исеци има боље перформансе од свих осталих структура података, осим у XLine тесту. Овај последњи детаљ има смисла јер је у том тесту вараијанса дуж $x$ осе мала, па соритрање и исецање не помаже. Са друге стране, сортирај и исеци је веома погодан у YLine тесту где је вариајанса велика. Као што смо дискутовали већ, ова нерегуларност може да се ублажи ако прво проверимо коју осу да користимо пре него што алгоритам почне.
Чудан феномен је да се квадратно стабло понаша много лошије у YLine него у XLine, иако је квадратно стабло непристрасна структура података. Прво сам помислио да је то зато што је простор тестова величине $800\times600$ пиксела, па су ентитети више проширени дуж $x$ што смањује пресецање, поготово јер су ентитети исте величине када су осе обрнуте у ова два теста, и стога би постојао већи пресек у $y$ оси. Чак и када иједначим обе осе, YLine тест и даље има лошије перформансе (али не толико лоше као пре). Још увек нисам сигуран зашто се ово дешава, али овим сам барем демонстрирао да је избор хиперпараметара веома важан.
R-стабла имају разочаравајуће перформансе, поготово стандардно R-стабло. Учитавање одједном помаже јер тада не долази до поновног убацивања чворова да би се стабло балансирало. Међу три имплементиране стратегије за учитавање одједном, најближе-X уводи најмањи overhead и даје задовољавајуће резултате. Једини изузетак је XLine тест, из истог разлога као и у сортирај и исеци; али можемо користити идентичну тактику одабира осе да би поправили перформансе.
K-d стабла имају лоше перформансе због константног сортирања низова да би се пронашла медијана. Као што сам споменуо, можемо користити друге технике за одређивање медијане које су брже али мање прецизне. Међутим, у овим тестовима је чак и медијан медијана (median of medians) алгоритам понашао лоше и зато га нисам користио у имплементацији и бенчмаркингу.
Желео бих да оставим пар напомена пре краја.
Прво, хиперпараметри за све ове стратегије су закуцане. Може се спровесит још много истраживања на одабиру вредности ових хиперпараметара користећи a priori информацију попут броја ентитета и дистрибуције ентитета. Да ли би ово побољшало перформансе стабала, не знам, а разлог је следећа напомена.
Друго, свака итерација теста се извршава тачно један фрејм. Да је извршавано више пута, онда би помоћне структуре података морале да се реконструишу сваки пут. Пошто је претпостављено да су ентитети статички, губили бисмо време узалуд. Можемо кеширати структуре података између фрејмова, искористивши претпоставку о временској кохерентности где би се јако мало тога променило између два суседна фрејма. Ставише, то би био најбољи приступ за динамичко окружење. Многе од ових структура података, поготово R-стабла и K-d стабла, подржавају убацивање и уклањање елемената што би генерално било јефтиније него реконструкција читавог стабла. Хајде да анализирамо колико времена је утрошено у изградњи структуре података у односу на читаво утрошено време. Резултати су у графицима испод.
Вредност $0$ би била идеална јер то значи да је читаво време потрошено на проналажење кандидата за колизију. Наивни приступ нема никакво претпроцесирање и зато је оно једино које може да достигне овај однос. Све остале структуре обављају неку комбинацију сортирања, хеширања и изградње стабла. Веће вредности су боље јер ако бисмо могли оптимизовати претпроцесирање, онда би укупно време било доста мање. Као што видимо, R-стабла имају највећи потенцијал за оптимизацију кроз кеширање, док су K-d стабла одмах иза њих.
Ово све излази из опсега за овај чланак, али бих волео да напишем други део овог чланка где је додат услов да су ентитети динамички. Поента ове приче сад је да постоји много простора за побољшање.
Закључак
Размотрили смо неколико метода за редуковање грешки првог реда у одређивању судара, од којих већина користи просторна стабла. Сви објекти чије се сударање проверава су сведени на правоугаонике поравнате са осама, ради једноставности. Већина чланка се фокусира на стицање интуиције иза ових приступа, објашњавајући математичке концепте и принципе који се користе за развој ових геометријских алгоритама.
Бенчмаркинг је показао да је алгоритам сортирај и одсеци (Sweep and Prune) има најбоље перформансе чак и када постоји хиљаде објеката који се секу. Штавише, сортирај и одсеци је много једноставнији за имплементацију од R-стабла или K-d стабла.
Резултати у овом чланку не треба да се узму здраво за готово: избор хиперпараметара множе драстично да утиче на резултате бенчмаркинга. Претпоставили смо да су сви ентитети статички, те уопште није разматрана гомила техника оптимизације у динамичким окружењима.